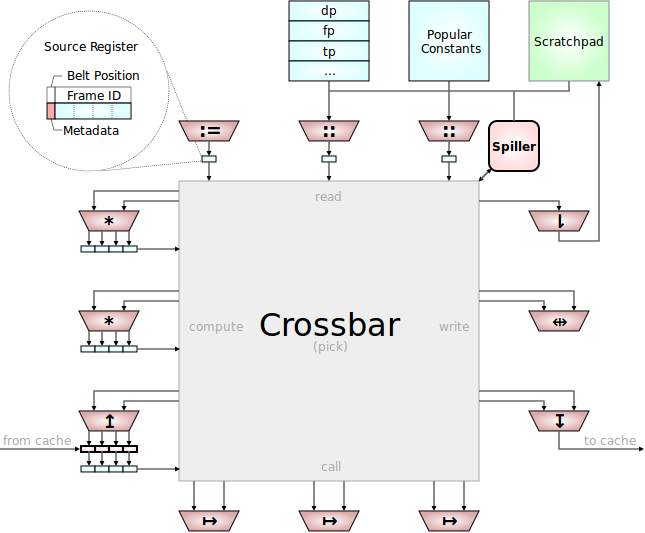
Crossbar
The Pipelines that are fed with operation requests from the decoder slots are connected to a big crossbar to feed them with data.
Contents
Sources and Sinks
One of the primary design goals of the Mill was to reduce the overall amount of data sources and data sinks, and especially to reduce the interconnection between them. Those interconnections between registers in conventional hardware are one of the primary energy and space consumers on those processors. Those connections must be very fast, because they must be immediately available, it's registers after all. And all registers can serve as a data source or a data sink to every functional unit. That is an explosion ends that need to be connected. This is even further exasperated by the large amount of rename registers necessary to do out-of-order computing.
On the Mill all this is vastly reduced in several ways.
Slots
For one, functional units are grouped into slots that share their input paths. With static scheduling they still can be fully utilized, but now a number of functional units only has at most 2 input paths for all of them together. Also, similar slots providing similar and related functionality are grouped together on the chip and can share some resources. Moreover neighboring slots can be connected with fast cheap data paths that don't require much switching to work together, via Ganging for example.
Output Registers and Source Registers
Moreover, each slot or pipeline that produces values for further consumption has a very limited amount of dedicated data sink registers only writable by the functional units in this slot. And those are even more specialized, in case there are operations of different latency within a pipeline. There are dedicated registers that only functional units of a specific latency can write in. In a given pipeline there are two sink registers for all functional units of the same latency together. This is a vast reduction of data paths in comparison to register machines. A very simple local addressing mechanism for registers serving as output destinations of a few functional units.
Now those same registers serve as source registers for the pipelines too. There they have another, global addressing mechanism that makes them available to the shared inputs of all pipelines. There are even short specialized fast paths for one latency operation results, so that they can be immediately consumed the next cycle by the next one latency operation in any slot after they were produced.
Addressing and Renaming Sources
The exact way how the sources are linked to the consumers is implementation dependent. Only code that belongs to the frame that produced them has access to them. And new frames are created by calls. Whenever a new value is created in a frame it gets the zero index in its new register and the indices of all other values in that frame are incremented.
Dimensioning
Generally the total amount of source registers on a chip is double that of the specified belt length. Each slot has double the sinks it can produce values every cycle. This means at any given moment at least half of the values in all the sources are dead values, but often they can come back to life on returns.
Slots Grouped into Phases
When looking at the chart you may have noticed that all the slots are ordered according to their inputs and outputs. This is how the operation phases of execution are defined. It's not only a logical distinction. The amount and kind of sources and sinks has direct impact on chip layout.
Reader
All the reader slots providing the functionality for the reader phase never read anything back from any of the source registers. They get their values from elsewhere. Both flow and exu streams have reader phase operations. The operations on the flow side, like const, directly receive their values from the instruction stream as immediates. That's why there is no visible input on the chart for this slot: the decoders and control flow hardware are left out.
All reader phase operations are one cycle operations. Immediately after decode the value can be dropped.
Special Sources
The exus side reader operations access internal state. This can be from all kinds of sources. The many of the special Registers can be read. The Spiller and Scratchpad can be explicitly queried. And then there is quite a large amount of predefined often used constants that would be cumbersome or wasteful to encode as constants in the instruction stream on the flow side.
Compute
In the compute phase both is needed, access to freshly created source values (although immediates are possible there too), and data sinks for future consumption. Each slot here can often produce several values in one cycle if operations of varying latency have been issued in the previous cycles. This is reflected in the amount of output registers, usually called latency registers here, because they are dedicated to specific latency operation results.
Gangs
Certain operations need or can benefit from more than one operand. But those are rare cases, and providing the data paths as general input paths is wasteful and expensive. This is why neighboring slots can send each other additional operands, and depending on the instructions issued they can either ignore them or use them. This working together forms Gangs.
Retire Stations
The load slots are in the compute phase too, although on the Flow side. They often need 2 dynamic inputs too, with a base address and an offset. The values produced come from cache or memory though, and as such those operations are explicitly delayed or can stall.
Since it is still possible to issue one new load every cycle, the load is kept alive in the retire stations, where the hardware awaits the values, and then issues them at the scheduled time.
Call
Calls only have inputs, usually an address and a condition. Although the target address can be an immediate too, and the condition can be omitted. It signals the decoder and control flow hardware.
Call Frames
Call units don't have dedicated output registers, because the values returned by a function cross the frame lines by register renaming. So while logically calls return values onto the belt, the values they return are already in some source register somewhere, that only needs to be renamed to be dropped into the caller 'a belt.
The values hoisted into the callees belt need to be copied though, because their values and belt positions must be preserved to restore the callers state on return. There is always enough room for that, due to the double amount of source registers to belt length. The spiller does the saving and restoring of older values if needed.
Pick
The pick operation has its own phase right after all calls, and it has zero latency. This is possible because it doesn't utilize any functional unit. The decoder directly reprograms the routing of the crossbar to change the data flow. All that is changing is the source for a predefined consumer.
Writer
Writer phase pipelines don't make any new sources available to the crossbar and the other phases. They do implement the operations that affect global system state, that have side effects and cant be reasoned solely within the belt programming model anymore though.
Hidden Sinks
The two most important things writer operations do is write into system memory with store and change control flow with branches. But there are also operations to store values in the Scratchpad as temporary storage for values that might be needed again soon.
The Spiller
The Spiller has his hands everywhere in the system. It monitors program flow, especially calls and how frames change, and all the sources and special registers and Scratchpad content, that are changed due to calls or other control flow, are saved and restored automatically. This happens transparently to the software. It doesn't even need to monitor all the source registers, only the last in the chain of the order they are written to. So while the spiller has its hands everywhere, it doesn't actually need that many data paths.
Implementation
The crossbar can be implemented in many different ways. Multiplexer trees, content addressable storage etc. What implementation is chosen depends on the requirements of a specific chip. The programming model is flexible enough to accommodate them all.
As mentioned above, latency one results need to be available in the next cycle. For this reason that big gray crossbar block is actually 2 chained crossbars, one for the fast path, one for everyone else.
What can be seen in the chart though is that there are no separate ExuCores and FlowCores. The pipelines belonging to each are freely intermixed, whatever is best. It is a purely conceptual distinction. What is real separate modules are the two decoders for the two instruction streams.
Media
Presentation on the Belt and Data Sources by Ivan Godard - Slides