Memory
A lot of the power and performance gains of the Mill, but also many of its security improvements over conventional architecures come from the various facilities of the memory management. Most subsystems have their own dedicated pages. This page is an overview.
Overview
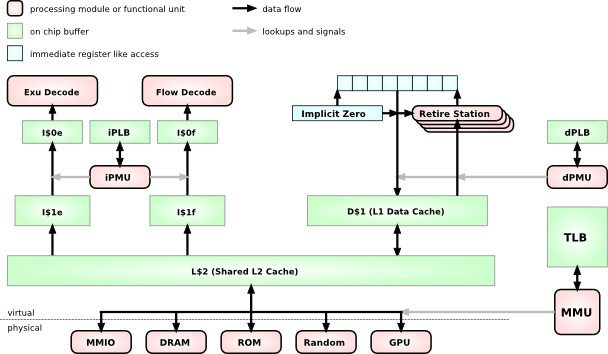
The Mill architecture is a 64bit architecture, there are no 32bit Mills. For this reason it is possible and indeed prudent to adopt a single address space (SAS) memory model. All threads and processes share the same address space. Any address points to the same location for every process. To do this securely and efficiently the memory access protection and address translation have been split into two separate modules, whereas on conventional architectures those two tasks are conflated into one.
As can be seen from this rough system chart, There is a combined L2 cache, although some low level implementations may choose to omit this for space and energy reasons. The Mill has facilities that make an L2 cache less critical.
L1 caches are separate for instructions and data already, and even more, they are already separate for ExuCore instrucions and FlowCore instructions. Smaller, more specialized caches can be made faster and more efficient in many regards, but chiefly via shorter signal paths.
The D$1 data cache feeds into the retire stations with load instructions and recieves the values from the store instructions.
Address Translation
Because address translation is separated from access protection, and because all processes share one address space, the translation and TLB accesses can be moved below the caches. In fact the TLB only ever needs to be accessed when there is a cache miss or evict. In that case there is a +300 cycle stall anyway, which means the TLB can be big and flat and slow and energy efficient. The few extra cycles for a TLB lookup are largely masked by the system memory access.
On conventional machines the TLB is right in the critical path between the top level cache and the functional units. This means the TLB must be small and with a complex hierarchy and fast and power hungry. And you still spend up to 20-30% of your cycles and power budget on TLB stalls and TLB hierarchy shuffling.
Reserved Address Space
The top 16th of the address space is reserved facilitate fast protection domain or turf switches with secure stacks. More on this there.
Virtual Zero
Caches
Media
Presentation on the Memory Hierarchy by Ivan Godard - Slides