Difference between revisions of "Memory"
m (fix links to load & store) | |||
| (23 intermediate revisions by 2 users not shown) | |||
| Line 1: | Line 1: | ||
| − | A lot of the power and performance gains of the Mill, but also many of its [[Protection|security]] improvements over conventional | + | A lot of the power and performance gains of the Mill, but also many of its [[Protection|security]] improvements over conventional architectures come from the various facilities of the memory management. Most subsystems have their own dedicated pages. This page is an overview. |
| − | <div style="position: absolute | + | <div style="position: absolute; left: 18em;"> |
<imagemap> | <imagemap> | ||
File:Memory-hierarchy.png|alt=Memory/Cache Hierarchy | File:Memory-hierarchy.png|alt=Memory/Cache Hierarchy | ||
| Line 10: | Line 10: | ||
== Overview == | == Overview == | ||
| − | The Mill architecture is a 64bit architecture | + | The Mill architecture is a 64bit architecture; there are no 32bit Mills. For this reason it is possible and indeed prudent to adopt a single address space (SAS) memory model. All threads and processes share the same address space. Any address points to the same location for every process. To do this securely and efficiently, the [[Protection|memory access protection]] and address translation have been split into two separate modules, whereas on conventional architectures those two tasks are conflated into one. |
As can be seen from this rough system chart, There is a combined L2 cache, although some low level implementations may choose to omit this for space and energy reasons. The Mill has facilities that make an L2 cache less critical.<br /> | As can be seen from this rough system chart, There is a combined L2 cache, although some low level implementations may choose to omit this for space and energy reasons. The Mill has facilities that make an L2 cache less critical.<br /> | ||
| − | L1 caches are separate for instructions and data already | + | L1 caches are separate for instructions and data already. Furthermore, they are separate for [[ExuCore]] instructions and [[FlowCore]] instructions. Smaller, more specialized caches can be made faster and more efficient chiefly via shorter signal paths.<br /> |
| − | The D$1 data cache feeds into the retire stations with [[Instruction Set/ | + | The D$1 data cache feeds into the retire stations with [[Instruction Set/load|load operations]] and receives the values from the [[Instruction Set/store|store operations]]. |
== [[Protection]] == | == [[Protection]] == | ||
| − | All [[Protection]] happens by defining protection attributes on virtual address regions. This happens above the Level 1 caches and separately for instructions and data with different attributes | + | All [[Protection]] happens by defining protection attributes on virtual address regions. This happens above the Level 1 caches and separately for instructions and data with different attributes; execute and portal for instructions, read and write for data. The <abbr title="instruction Protection Lookaside Buffer">iPLB</abbr> and <abbr title="data Protection Lookaside Buffer">dPLB</abbr> lookup tables are specialized and can be small and fast. And even better optimizations exist in the [[Protection#Well_Known_Regions|well known regions]] for the most common cases. More on this under [[Protection]]. |
== Address Translation == | == Address Translation == | ||
| − | Because address translation is separated from access protection, and because all processes share one address space, the translation and <abbr title="Translation Lookaside Buffer">TLB</abbr> accesses can be moved below the caches. In fact the TLB only ever needs to be accessed when there is a cache miss or evict. In that case there is a +300 cycle stall anyway, which means the TLB can be big | + | Because address translation is separated from access protection, and because all processes share one address space, the translation and <abbr title="Translation Lookaside Buffer">TLB</abbr> accesses can be moved below the caches. In fact the TLB only ever needs to be accessed when there is a cache miss or evict. In that case there is a +300 cycle stall anyway, which means the TLB can be big, flat, slow, and energy efficient. The few extra cycles for a TLB lookup are largely masked by the system memory access.<br /> |
| − | On conventional machines the TLB is right in the critical path between the top level cache and the functional units. This means the TLB must be small and with a complex hierarchy | + | On conventional machines the TLB is right in the critical path between the top level cache and the functional units. This means the TLB must be small, fast, and power hungry with a complex hierarchy. And you still spend up to 20-30% of your cycles and power budget on TLB stalls and TLB hierarchy shuffling. |
=== Reserved Address Space === | === Reserved Address Space === | ||
| − | The top | + | The virtual address space is 60bit. This is because the top 4 bits of the [[Virtual Address]]es are reserved for system use like garbage collection. |
| + | |||
| + | The top part of this 60bit address space is reserved to facilitate fast [[Protection#Stacklets|protection domain or turf]] switches with secure stacks. More on this there. | ||
== Retire Stations == | == Retire Stations == | ||
| − | Retire stations | + | Retire stations serve the load/store <abbr title="Functional Unit">FU</abbr>s or [[Slot]] for the [[Instruction Set/load|load operation]]. They implement the deferred load operation and conceptually are part of the [[FlowCore]]. The load operation is explicitly deferred, i.e. it has a parameter which determines exactly at which point in the future it has to make the value available and drop it on the [[Belt]]. This explicit static but parametrized scheduling allows the hiding of almost all cache latencies in memory access. A DRAM stall will still have the same cost, but due to innovations in cache access, specialized mechanisms for the most common memory access patterns, and exact [[Prediction]], the amount of DRAM accesses has been vastly reduced.<br /> |
| − | Another important aspect of this deferred load operation is | + | Another important aspect of this deferred load operation is that it will not load the value at the point of the issuing of the load operation, but at the point when it is scheduled to yield the value. This makes the load hardware immune to [[Aliasing]], which means the compiler can stop worrying about aliasing completely and aggressively optimize.<br /> |
| − | This is achieved | + | This is achieved when the active retire stations, i.e. the retire stations that have a load pending to return, monitor the store wires for stores on their address. And whenever they see there is a store on their address, they copy the value for later return. |
== Implicit Zero and Virtual Zero == | == Implicit Zero and Virtual Zero == | ||
| Line 39: | Line 41: | ||
Loads from uninitialized but accessible memory always yield zero on the Mill. There are two mechanisms to ensure that. | Loads from uninitialized but accessible memory always yield zero on the Mill. There are two mechanisms to ensure that. | ||
| − | The first is virtual zero. When a load misses the caches and also misses the <abbr title="Translation Lookaside Buffer">TLB</abbr> with no <abbr title="Page Table Entry">PTE</abbr> in it, it means there have been no stores to the address yet, and in this case the <abbr title="Memory Management Unit">MMU</abbr> returns zero for the load to bring back to the retire station. The big gain for this is that the OS doesn't have to explicitly zero out new pages, which would be a lot of bandwidth and time | + | The first is virtual zero. When a load misses the caches and also misses the <abbr title="Translation Lookaside Buffer">TLB</abbr> with no <abbr title="Page Table Entry">PTE</abbr> in it, it means there have been no stores to the address yet, and in this case the <abbr title="Memory Management Unit">MMU</abbr> returns zero for the load to bring back to the retire station. The big gain for this is that the OS doesn't have to explicitly zero out new pages, which would be a lot of bandwidth and time. And accesses to uninitialized memory only take the time of the cache and TLB lookups instead of having to do memory round trips.<br /> |
This also has security benefits, since no one can snoop on memory garbage piles. | This also has security benefits, since no one can snoop on memory garbage piles. | ||
| − | An optimization of this for data stacks is the implicit zero. The problems of uninitialized memory and | + | An optimization of this for data stacks is the implicit zero. The problems of uninitialized memory and bandwidth waste are that the virtual zero addresses for general memory accesses are even more compounded for the data stack. This is because of the high frequency of new accesses and the frequency with which recently written data is never used again. On conventional architectures this causes a staggering amount of cache thrashing and superfluous memory accesses.<br /> |
The [[Instruction Set/Stackf|stackf]] instruction allocates a new stack frame, i.e. a number of new cache lines, but it does so just by putting markers for those cache lines into the implicit zero registers.<br /> | The [[Instruction Set/Stackf|stackf]] instruction allocates a new stack frame, i.e. a number of new cache lines, but it does so just by putting markers for those cache lines into the implicit zero registers.<br /> | ||
| − | When a subsequent load happens on a newly allocated stack frame, the hardware knows it is a stack access due to the [[Protection#Well_Known_Regions|well known region]] and stack frame [[Registers]]. The hardware doesn't even need to check the [[Protection|dPLB]] or the top level caches, it just returns zero. So while virtual zero returns zero with only the cost of the cache accesses for uninitialized memory | + | When a subsequent load happens on a newly allocated stack frame, the hardware knows it is a stack access due to the [[Protection#Well_Known_Regions|well known region]] and stack frame [[Registers]]. The hardware doesn't even need to check the [[Protection|dPLB]] or the top level caches, it just returns zero. So while virtual zero returns zero with only the cost of the cache accesses for uninitialized memory. For the most frequent case of uninitialized stack accesses, there are not top level cache delays, just immediate access. And of course it also makes it impossible to snoop on old stack frames.<br /> |
| − | Only when a [[Instruction Set/Store|store]] happens on a new stack frame will an actual new cache line be allocated, the new value be written and | + | Only when a [[Instruction Set/Store|store]] happens on a new stack frame will an actual new cache line be allocated, the new value be written, and those values be marked as written by a flag in the implicit zero registers, all by hardware. Uninitialized loads are still implicitly zero in this cache line; only the actually stored value is pulled from the cache. |
| + | |||
| + | In the majority of cases the stack frame is deallocated before it ever has been written to memory, and the cache line can just be discarded and freed up for future use. | ||
== Data Cache == | == Data Cache == | ||
| Line 57: | Line 61: | ||
All stores are to the top of the data cache, and thus are neither write-back nor write-through. And, by definition, stores cannot miss the cache and don't involve memory. Cache lines can be evicted to lower levels. And when they are loaded again they are hoisted up again. When there are cache lines for the same address on multiple levels, they get merged on evict or hoist, with the upper level winning if both bytes are valid. In the above example, after the width 16 load, you would have the full merged string "StKill the wabbit\0" on the top level cache. | All stores are to the top of the data cache, and thus are neither write-back nor write-through. And, by definition, stores cannot miss the cache and don't involve memory. Cache lines can be evicted to lower levels. And when they are loaded again they are hoisted up again. When there are cache lines for the same address on multiple levels, they get merged on evict or hoist, with the upper level winning if both bytes are valid. In the above example, after the width 16 load, you would have the full merged string "StKill the wabbit\0" on the top level cache. | ||
| − | All this usually happens without any physical memory involvement | + | All this usually happens completely in cache without any physical memory involvement. It is backless memory and a vast improvement in all access times. And because all this happens in cache with the valid bit mechanisms, there are also no alignment penalties for loads and stores of data types of different widths. The load and store operations only support power of two widths for the data, but they can be on addresses of any alignment without penalty. |
If there are still invalid bytes left at the lowest cache level, and there is a <abbr title="Page Table Entry">PTE</abbr> for the cache line, then of course the remaining bytes are taken from memory, and the line is hoisted from memory and merged. But for that to happen a line first has to be completely evicted to physical memory, and then new writes without intermediate loads have to have created new lines in cache for the addresses in the line.<br /> | If there are still invalid bytes left at the lowest cache level, and there is a <abbr title="Page Table Entry">PTE</abbr> for the cache line, then of course the remaining bytes are taken from memory, and the line is hoisted from memory and merged. But for that to happen a line first has to be completely evicted to physical memory, and then new writes without intermediate loads have to have created new lines in cache for the addresses in the line.<br /> | ||
| − | As a result the cases where actual access to physical memory is necessary have been vastly reduced. And often the temporary data in smaller subroutines never gets into physical memory at all | + | As a result the cases where actual access to physical memory is necessary have been vastly reduced. And often the temporary data in smaller subroutines never gets into physical memory at all so the whole lifetime of the objects has been spent in cache. |
=== Memory Allocation === | === Memory Allocation === | ||
| − | Only when a lowest level cache line | + | Only when a lowest level cache line is evicted does an actual memory page get allocated. And even this happens completely in hardware with cache line size pages and a bit map allocator from a hierarchy with larger pages. Invalid bits are still set to 0 by the MMU.<br /> |
It is those larger pages that are managed by the OS in traps raised by the <abbr title="Memory Management Unit">MMU</abbr> when it runs low on backing memory pages.<br /> | It is those larger pages that are managed by the OS in traps raised by the <abbr title="Memory Management Unit">MMU</abbr> when it runs low on backing memory pages.<br /> | ||
| − | A big advantage of this allocation behavior is | + | A big advantage of this allocation behavior is that in the vast majority of cases you only get to write into memory when a larger number of writes has accumulated in cache already, and they are written all at once. In contrast to write-back caches, where this is also the case, you don't always need to evict a cache line on a read miss. This is because you can often just merge the memory backing into the invalid bytes of the existing cache line. Only a read from a truly cold and unpredicted and thus unprefetched line triggers an evict that causes a stall. A store into a cold line triggers an evict too, after it cascaded down the caches, but this evict almost never causes a stall since the evicted line is most likely a cold line. |
== Instruction Cache == | == Instruction Cache == | ||
| − | The instruction caches are | + | The instruction caches are read only. And as mentioned before, they are specialized to their Instruction stream. This means they are managed differently from the data caches to facilitate better instruction [[Prediction#Prefetch_and_Fetch|prefetch]] and [[Decode]] without bubbles in the pipeline. More in this on the respective pages. |
== Sequential Consistency == | == Sequential Consistency == | ||
All memory accesses happen in the order they occur in the program. This is sequential consistency. No access reordering happens, and consequently there is no need for memory fences and the like.<br /> | All memory accesses happen in the order they occur in the program. This is sequential consistency. No access reordering happens, and consequently there is no need for memory fences and the like.<br /> | ||
| − | Loads and stores may be placed in the same instruction or retire in the same cycle, and as such are issued and executed in parallel. But the order they retire in is still | + | Loads and stores may be placed in the same instruction or retire in the same cycle, and as such are issued and executed in parallel. But the order they retire in is still determined by the order they appear in the instruction, and as such by the order of the [[Slot]]s they were issued into.<br /> |
This order is not only maintained on a single core, but a defined order for all cores on a chip is maintained with the cache coherency protocol. | This order is not only maintained on a single core, but a defined order for all cores on a chip is maintained with the cache coherency protocol. | ||
== [[Spiller]] == | == [[Spiller]] == | ||
| − | The spiller is a dedicated central hardware module that preserves internal core state for as long as it may be needed. As such it may save internal core state to dedicated DRAM areas, the spiller space. This memory is not accessible by any other mechanism, and no other hardware mechanisms can interfere with the spiller and meddle with its own internal state. | + | The spiller is a dedicated central hardware module that preserves internal core state for as long as it may be needed. As such it may save internal core state to dedicated DRAM areas, i.e. the spiller space. This memory is not accessible by any other mechanism, and no other hardware mechanisms can interfere with the spiller and meddle with its own internal state. Spiller memory accesses don't need to go through the [[Protection]] layer, since no one can make the spiller to do anything insecure. It uses the L2 cache as a buffer and everything still goes through address translation, because special system tools like [[Debugger]]s occasionally need to read spiller state.<br /> |
| − | + | ||
== [[Streamer]] == | == [[Streamer]] == | ||
| Line 87: | Line 90: | ||
== Rationale == | == Rationale == | ||
| − | Memory latency is the main bottleneck that dictates how modern processors are designed. Memory latency is the reason why all the expensive out-of-order hardware is so prevalent on virtually all general purpose processors since the 60s. If anything the steadily increasing gap in frequency between memory and processor cores makes the latency even more | + | Memory latency is the main bottleneck that dictates how modern processors are designed. Memory latency is the reason why all the expensive out-of-order hardware is so prevalent on virtually all general purpose processors since the 60s. If anything the steadily increasing gap in frequency between memory and processor cores makes the latency felt even more today. |
| − | So hiding the latency of the memory accesses and reducing the amount of memory accesses are the primary goals in any processor architecture. Both is mainly achieved with the use of caches. Sophisticated [[Prediction]] and | + | So hiding the latency of the memory accesses and reducing the amount of memory accesses are the primary goals in any processor architecture. Both is mainly achieved with the use of caches. Sophisticated [[Prediction]] and prefetch fills the caches as far in advance as possible. [[Instruction_Set/load|Load]] and [[Instruction_Set/store|store]] deferring and [[Pipelining]] and [[Speculation]] hide the cache latencies, and increase the levels of <abbr title="Instruction Level Parallelism">IPL</abbr> for loads and stores by making memory accesses less dependent on each other. And the cache management protocols determine the amount of actual memory accesses. |
All three aspects have new solutions on the Mill. Generally those solutions are not really more powerful or faster than the solutions of conventional out-of-order architectures. They are only vastly cheaper. Truly random and unpredictable work loads still can't be helped though. | All three aspects have new solutions on the Mill. Generally those solutions are not really more powerful or faster than the solutions of conventional out-of-order architectures. They are only vastly cheaper. Truly random and unpredictable work loads still can't be helped though. | ||
| + | |||
| + | == See Also == | ||
| + | |||
| + | [[Spiller]], [[Virtual Addresses]] | ||
== Media == | == Media == | ||
[http://www.youtube.com/watch?v=bjRDaaGlER8 Presentation on the Memory Hierarchy by Ivan Godard] - [http://millcomputing.com/blog/wp-content/uploads/2013/12/2013-10-16_mill_cpu_hierarchy_08.pptx Slides] | [http://www.youtube.com/watch?v=bjRDaaGlER8 Presentation on the Memory Hierarchy by Ivan Godard] - [http://millcomputing.com/blog/wp-content/uploads/2013/12/2013-10-16_mill_cpu_hierarchy_08.pptx Slides] | ||
Latest revision as of 21:11, 9 June 2015
A lot of the power and performance gains of the Mill, but also many of its security improvements over conventional architectures come from the various facilities of the memory management. Most subsystems have their own dedicated pages. This page is an overview.
Contents
Overview
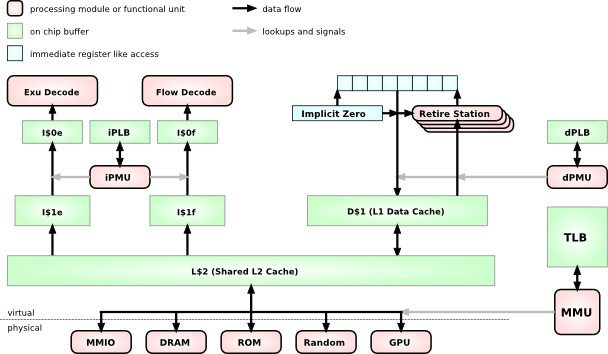
The Mill architecture is a 64bit architecture; there are no 32bit Mills. For this reason it is possible and indeed prudent to adopt a single address space (SAS) memory model. All threads and processes share the same address space. Any address points to the same location for every process. To do this securely and efficiently, the memory access protection and address translation have been split into two separate modules, whereas on conventional architectures those two tasks are conflated into one.
As can be seen from this rough system chart, There is a combined L2 cache, although some low level implementations may choose to omit this for space and energy reasons. The Mill has facilities that make an L2 cache less critical.
L1 caches are separate for instructions and data already. Furthermore, they are separate for ExuCore instructions and FlowCore instructions. Smaller, more specialized caches can be made faster and more efficient chiefly via shorter signal paths.
The D$1 data cache feeds into the retire stations with load operations and receives the values from the store operations.
Protection
All Protection happens by defining protection attributes on virtual address regions. This happens above the Level 1 caches and separately for instructions and data with different attributes; execute and portal for instructions, read and write for data. The iPLB and dPLB lookup tables are specialized and can be small and fast. And even better optimizations exist in the well known regions for the most common cases. More on this under Protection.
Address Translation
Because address translation is separated from access protection, and because all processes share one address space, the translation and TLB accesses can be moved below the caches. In fact the TLB only ever needs to be accessed when there is a cache miss or evict. In that case there is a +300 cycle stall anyway, which means the TLB can be big, flat, slow, and energy efficient. The few extra cycles for a TLB lookup are largely masked by the system memory access.
On conventional machines the TLB is right in the critical path between the top level cache and the functional units. This means the TLB must be small, fast, and power hungry with a complex hierarchy. And you still spend up to 20-30% of your cycles and power budget on TLB stalls and TLB hierarchy shuffling.
Reserved Address Space
The virtual address space is 60bit. This is because the top 4 bits of the Virtual Addresses are reserved for system use like garbage collection.
The top part of this 60bit address space is reserved to facilitate fast protection domain or turf switches with secure stacks. More on this there.
Retire Stations
Retire stations serve the load/store FUs or Slot for the load operation. They implement the deferred load operation and conceptually are part of the FlowCore. The load operation is explicitly deferred, i.e. it has a parameter which determines exactly at which point in the future it has to make the value available and drop it on the Belt. This explicit static but parametrized scheduling allows the hiding of almost all cache latencies in memory access. A DRAM stall will still have the same cost, but due to innovations in cache access, specialized mechanisms for the most common memory access patterns, and exact Prediction, the amount of DRAM accesses has been vastly reduced.
Another important aspect of this deferred load operation is that it will not load the value at the point of the issuing of the load operation, but at the point when it is scheduled to yield the value. This makes the load hardware immune to Aliasing, which means the compiler can stop worrying about aliasing completely and aggressively optimize.
This is achieved when the active retire stations, i.e. the retire stations that have a load pending to return, monitor the store wires for stores on their address. And whenever they see there is a store on their address, they copy the value for later return.
Implicit Zero and Virtual Zero
Loads from uninitialized but accessible memory always yield zero on the Mill. There are two mechanisms to ensure that.
The first is virtual zero. When a load misses the caches and also misses the TLB with no PTE in it, it means there have been no stores to the address yet, and in this case the MMU returns zero for the load to bring back to the retire station. The big gain for this is that the OS doesn't have to explicitly zero out new pages, which would be a lot of bandwidth and time. And accesses to uninitialized memory only take the time of the cache and TLB lookups instead of having to do memory round trips.
This also has security benefits, since no one can snoop on memory garbage piles.
An optimization of this for data stacks is the implicit zero. The problems of uninitialized memory and bandwidth waste are that the virtual zero addresses for general memory accesses are even more compounded for the data stack. This is because of the high frequency of new accesses and the frequency with which recently written data is never used again. On conventional architectures this causes a staggering amount of cache thrashing and superfluous memory accesses.
The stackf instruction allocates a new stack frame, i.e. a number of new cache lines, but it does so just by putting markers for those cache lines into the implicit zero registers.
When a subsequent load happens on a newly allocated stack frame, the hardware knows it is a stack access due to the well known region and stack frame Registers. The hardware doesn't even need to check the dPLB or the top level caches, it just returns zero. So while virtual zero returns zero with only the cost of the cache accesses for uninitialized memory. For the most frequent case of uninitialized stack accesses, there are not top level cache delays, just immediate access. And of course it also makes it impossible to snoop on old stack frames.
Only when a store happens on a new stack frame will an actual new cache line be allocated, the new value be written, and those values be marked as written by a flag in the implicit zero registers, all by hardware. Uninitialized loads are still implicitly zero in this cache line; only the actually stored value is pulled from the cache.
In the majority of cases the stack frame is deallocated before it ever has been written to memory, and the cache line can just be discarded and freed up for future use.
Data Cache
All data caches and shared caches have 9 bits per byte. The additional bit is the valid bit. Whenever a new cache line is allocated, always because of a store to a new location, the new value is set for the bytes of the store and their valid bits are set. All other bytes remain invalid.
Backless Memory

All stores are to the top of the data cache, and thus are neither write-back nor write-through. And, by definition, stores cannot miss the cache and don't involve memory. Cache lines can be evicted to lower levels. And when they are loaded again they are hoisted up again. When there are cache lines for the same address on multiple levels, they get merged on evict or hoist, with the upper level winning if both bytes are valid. In the above example, after the width 16 load, you would have the full merged string "StKill the wabbit\0" on the top level cache.
All this usually happens completely in cache without any physical memory involvement. It is backless memory and a vast improvement in all access times. And because all this happens in cache with the valid bit mechanisms, there are also no alignment penalties for loads and stores of data types of different widths. The load and store operations only support power of two widths for the data, but they can be on addresses of any alignment without penalty.
If there are still invalid bytes left at the lowest cache level, and there is a PTE for the cache line, then of course the remaining bytes are taken from memory, and the line is hoisted from memory and merged. But for that to happen a line first has to be completely evicted to physical memory, and then new writes without intermediate loads have to have created new lines in cache for the addresses in the line.
As a result the cases where actual access to physical memory is necessary have been vastly reduced. And often the temporary data in smaller subroutines never gets into physical memory at all so the whole lifetime of the objects has been spent in cache.
Memory Allocation
Only when a lowest level cache line is evicted does an actual memory page get allocated. And even this happens completely in hardware with cache line size pages and a bit map allocator from a hierarchy with larger pages. Invalid bits are still set to 0 by the MMU.
It is those larger pages that are managed by the OS in traps raised by the MMU when it runs low on backing memory pages.
A big advantage of this allocation behavior is that in the vast majority of cases you only get to write into memory when a larger number of writes has accumulated in cache already, and they are written all at once. In contrast to write-back caches, where this is also the case, you don't always need to evict a cache line on a read miss. This is because you can often just merge the memory backing into the invalid bytes of the existing cache line. Only a read from a truly cold and unpredicted and thus unprefetched line triggers an evict that causes a stall. A store into a cold line triggers an evict too, after it cascaded down the caches, but this evict almost never causes a stall since the evicted line is most likely a cold line.
Instruction Cache
The instruction caches are read only. And as mentioned before, they are specialized to their Instruction stream. This means they are managed differently from the data caches to facilitate better instruction prefetch and Decode without bubbles in the pipeline. More in this on the respective pages.
Sequential Consistency
All memory accesses happen in the order they occur in the program. This is sequential consistency. No access reordering happens, and consequently there is no need for memory fences and the like.
Loads and stores may be placed in the same instruction or retire in the same cycle, and as such are issued and executed in parallel. But the order they retire in is still determined by the order they appear in the instruction, and as such by the order of the Slots they were issued into.
This order is not only maintained on a single core, but a defined order for all cores on a chip is maintained with the cache coherency protocol.
Spiller
The spiller is a dedicated central hardware module that preserves internal core state for as long as it may be needed. As such it may save internal core state to dedicated DRAM areas, i.e. the spiller space. This memory is not accessible by any other mechanism, and no other hardware mechanisms can interfere with the spiller and meddle with its own internal state. Spiller memory accesses don't need to go through the Protection layer, since no one can make the spiller to do anything insecure. It uses the L2 cache as a buffer and everything still goes through address translation, because special system tools like Debuggers occasionally need to read spiller state.
Streamer
Rationale
Memory latency is the main bottleneck that dictates how modern processors are designed. Memory latency is the reason why all the expensive out-of-order hardware is so prevalent on virtually all general purpose processors since the 60s. If anything the steadily increasing gap in frequency between memory and processor cores makes the latency felt even more today.
So hiding the latency of the memory accesses and reducing the amount of memory accesses are the primary goals in any processor architecture. Both is mainly achieved with the use of caches. Sophisticated Prediction and prefetch fills the caches as far in advance as possible. Load and store deferring and Pipelining and Speculation hide the cache latencies, and increase the levels of IPL for loads and stores by making memory accesses less dependent on each other. And the cache management protocols determine the amount of actual memory accesses.
All three aspects have new solutions on the Mill. Generally those solutions are not really more powerful or faster than the solutions of conventional out-of-order architectures. They are only vastly cheaper. Truly random and unpredictable work loads still can't be helped though.
See Also
Media
Presentation on the Memory Hierarchy by Ivan Godard - Slides