Difference between revisions of "Crossbar"
| Line 34: | Line 34: | ||
=== Reader === | === Reader === | ||
| − | ==== Special Sources === | + | ==== Special Sources ==== |
=== Compute === | === Compute === | ||
| Line 44: | Line 44: | ||
=== Writer === | === Writer === | ||
| − | ==== Hidden Sinks === | + | ==== Hidden Sinks ==== |
== The Spiller == | == The Spiller == | ||
Revision as of 22:44, 9 August 2014
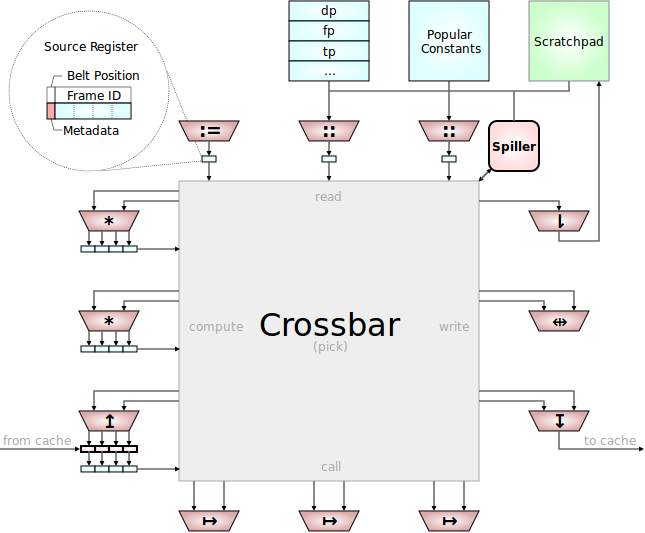
The Slots that are fed with operation requests from the decoder are connected to a big crossbar to feed them with data.
Contents
Sources and Sinks
One of the primary design goals of the Mill was to reduce the overall amount of data sources and data sinks, and especially to reduce the interconnection between them. Those interconnections between registers in conventional hardware are one of the primary energy and space consumers on those processors. Those connections must be very fast, because they must be immediately available, it's registers after all. And all registers can serve as a data source or a data sink to every functional unit. That is an explosion ends that need to be connected. This is even further exasperated by the large amount of rename registers necessary to do out-of-order computing.
On the Mill all this is vastly reduced in several ways.
Slots
For one, functional units are grouped into slots that share their input paths. With static scheduling they still can be fully utilized, but now a number of functional units only has at most 2 input paths for all of them together. Also, similar slots providing similar and related functionality are grouped together on the chip and can share some resources. Moreover neighboring slots can be connected with fast cheap datapaths that don't require much switching to work together, via Ganging for example.
Output Registers and Source Registers
Moreover, each slot or pipeline that produces values for further consumption has a very limited amount of dedicated data sink registers only writable by the functional units in this slot. And those are even more specialized, in case there are operations of different latency within a pipeline. There are dedicated registers that only functional units of a specific latency can write in. In a given pipeline there are two sink registers for all functional units of the same latency together. This is a vast reduction of data paths in comparison to register machines. A very simple local addressing mechanism for registers serving as output desitinatins of a few functional units.
Now those same registers serve as source registers for the piplelines too. There they have another, global addressing mechanism that makes them available to the shared inputs of all pipelines. There are even short specialized fast paths for one latency operation results, so that they can be immediately consumed the next cycle by the next one latency operation in any slot after they were produced.